Control Groups
Look at the title of this post, during the remaining lines of it you will be reading either about a 1930s fascist Italy special police corps or, of course, about a linux kernel feature, lucky for you that I don’t feel like complaining about the intriguing ability of politicians to put fancy names to the most abominable ideas and probably other posts will come on that subject, but this one is about the kernel feature called control groups.
We’ve all seen the fuss around docker, lots of people have been talking about it in the recent years and some of them even know what they’re talking about. Docker, and in general containers, whether you care or not, are heavily disrupting the scene and I just thought some of you might be interested in getting to know a little bit about some of the clever and sophisticated pieces of machinery that made it all possible.
PLEASE DO NOT use this post as a technical reference, it’s meant to be simply a conceptual intro to control groups and the way they are used by containers, we won’t dive too deep so the concepts exposed won’t be extremely complex, you don’t need to know much about containers or about GNU/linux beyond the basics, let’s roll.
The Concept
Since you know the basic stuff about containers, let’s cut to the chase, containerization technologies such as docker and rkt are supposed to, among many other things, limit and keep track of the share of actual resources (CPU, RAM, IO, Network…) that every running container gets in order to account for the resources used and to ensure that containers are truly isolated from one another, that is to say, the lovely people developing docker and rkt needed a mechanism that allowed them to do precisely that, and they didn’t have to look too far, the linux kernel happened to have exactly that mechanism already built in for quite some time, it’s called control groups. It’s a good time to mention that most technologies on which containers built on have existed for a while, even the idea of putting them together have existed for some time as well, it’s called LXC, but that’s a whole different story.
So what is control groups all about? It’s all about resources (CPU, RAM, IO, Network…) and the way they get distributed across the process tree, and what is a running container if not simply a branch in the process tree. Control groups actually have many more uses, but in this post we’ll focus only on distribution of resources.
But how does control groups do what it does? Well, it’s quite simple, it groups processes so that certain constraints on resources can be applied to each group, every group is formed by a branch of the process tree and has a set of parameters associated to it, every one of these groups is called a control group. There’s a little more to it, but let’s stick to that definition by now.
The Subsystems
One of the interesting design decision made by the kernel developers when developing control groups is that control groups itself shouldn’t deal with any resource at all, it should only expose an interface through which the components of the kernel that DO deal with resources could distribute the resource that each one of them manages across the process tree, in control groups terminology these components are called subsystems and they are one type of the clients that consume the interface that control groups exposes in order to do the actual distribution of resources.
The Example
Let’s say you have two containers, container A and container B, and to keep it simple let’s say you need to apply constraints on each container only regarding CPU and memory,
| Container | Memory Constraint | CPU Constraint |
|---|---|---|
| Container A | Max. 2 GB | Only CPU 1 |
| Container B | Max. 4 GB | Only CPU 2 |
so, container A should be able to allocate no more than 2 GB of RAM memory and container B no more than 4 GB, container A should run only on CPU 1 and container B should run only on CPU 2, when running those containers the process tree of the imaginary linux system on which they are running should look like this,
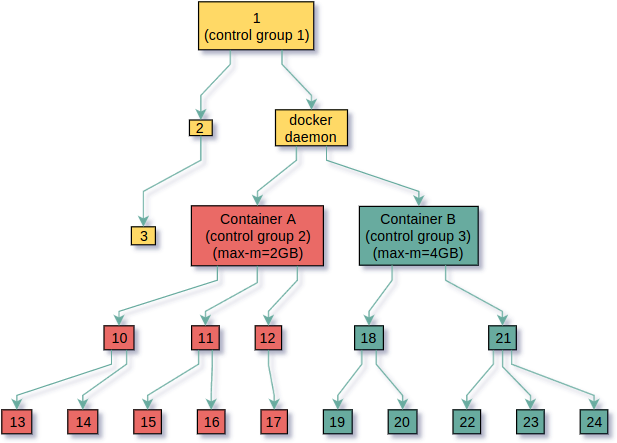
when container A is run, docker or rkt, will create a control group and put a parameter on it that says that all processes belonging to that control group shall not be able to use more than 2 GB of physical memory, and when container B is run another control group will be created with the same parameter indicating that no more than 4 GB should be used by the processes belonging to that control group. Later on, the memory subsystem of the kernel will read the parameters on those control groups and will act accordingly by limiting the amount of memory that can be used by the processes on those control groups.
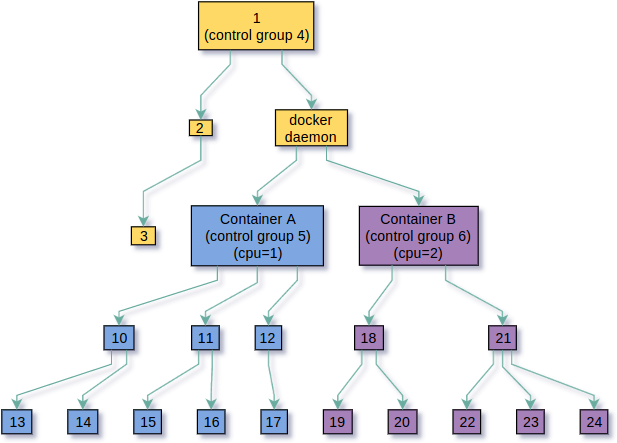
here, the same happens with CPU constraints, for every container a control group is created with a parameter on it indicating on which CPU its processes are allowed to run.
The Hierarchy
As you can see in the next pictures, when control groups are created across the process tree, a new hierarchy emerges, this time not made of processes but made of control groups themselves, in control groups terminology it’s unsurprisingly called a hierarchy.
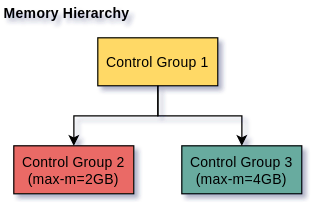
The important thing about hierarchies and the reason why they are so powerful is that many independent hierarchies can be created and each one of them offers a different view of the process tree in such a way that every subsystem of the kernel might have its own isolated view of the entire process tree, this design decision is very clever because it gives subsystems the freedom to NOT share control groups if they don’t want to.
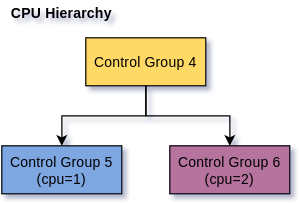
Containers don’t make a heavy use of this feature, see why? Yes, a container is a single set of processes and hence, all constraints that need to be applied to the container will be applied to the same set of processes, that is, every control group created to manage a resource for a single container will apply to the same set of processes that every other control group created to manage every other resource, for what it’s worth all subsystems could share the same hierarchy of control groups and it wouldn’t make a big difference for containers, however there are many other applications in which this feature happens to be extremely useful, and keep in mind that control groups were not designed thinking about containers, it’s a much more general feature of the linux kernel.
The Performance
At this point the inquisitive minds could be tempted to think that control groups, with all its complexities, might be an overhead for a container, the truth is, it is NOT, it doesn’t incur in any noticeable overhead since, as we said before, control groups never deal with system resources directly, for the most part it is just additional bits of data on already existing data structures and on the other hand every time you boot your linux system, default hierarchies and default control groups are created on your process tree, so even when you’re not using containers you are using control groups.
The End (for now)
This was a rather superficial review of control groups, by no means it was intended to be an extensive explanation of its inner mechanisms and concepts that as you can imagine would require many more pages, and many concepts have been oversimplified in order to make them easily understandable, if you want to dig way deeper you can take a look at the kernel docs where besides you will find a nice example for a practical use of hierarchies. In another post we’ll have a more practical approach and we’ll take a look at the concrete details of the control groups interface and the way containers make use of it, so, stay tuned and thank you for reading.